
Как появился и как работает штрих-код (простым языком)

Каждый день человек сталкивается с такой полезной штуковиной, как штрихкод. Однако, делая покупки в магазине, мало кто из нас задумывается над тем, как эта штуковина вообще работает.
Каким образом из линий разной толщины или даже формы получается заветный ценник?
Итак, самое время попробовать разобраться в первом приближении с принципом действия штрихкодов и сканеров для их считывания, поговорить о том, какие они бывают, когда и для чего вообще появились.
1. Что такое штрихкод и зачем он нужен?

Кэп говорит, что штрихкод для кодирования нужен.
Начать стоит с определения. Штриховой код – это способ графического кодирования двоичной системы исчисления. В свою очередь двоичная система исчисления – это позиционная система исчисления, состоящая из нулей (0) и единиц (1). Важнейшее качество и достоинство двоичной системы в том, что она является математическим выражением простейшей (бинарной) логики «да»/«нет» или «истина»/«верно». Это в свою очередь позволяет применять ее в цифровых электронных схемах на логических вентилях.
Таким образом двоичная система является основой работы почти всей современной микроэлектроники от наручных часов до смартфонов и компьютеров. При этом у двоичной системы есть предсказуемый минус. Закодированные цифры и буквы при попытке графического отображения занимают много места. Например, латинская «А» будет выглядеть как 01000001, а число «69» будет выглядеть как 1000101.
При этом на заре развития микроэлектроники (компьютеров) имеющиеся технологии не позволяли людям создать оборудование, способное распознавать «сложные» изображения. Это сегодня компьютеры умеют находить похожие изображения, а нейросети создают собственные тексты, музыку и рисунки. В 1940-е годы считывание простейших цифр и букв с поверхности было чем-то вроде научной фантастики. Поэтому люди и придумали штрихкод - инструмент, который позволяет сделать «сложную» графическую информацию «простой» для считывающего оборудования.
2. Как вообще штрихкод появился?

Дружно скажем спасибо компании IBM.
Как у всякого сложного изобретения, у штрихового кода нет его «папы и мамы» в лице одного творца. Современный штриховой код был продуктом творчества и научных изысканий большого количества людей. У истоков создания штрихкода в 1948 году стоял аспирант Технологического института при Дрексельском университете в Филадельфии Бернард Сильвер, который пытался разработать систему автоматического считывания о продукте при его контроле для местной торговой сети. Он подтянул к работе своих друзей Нормана Джозефа Вудланда и Джордина Йохансона. Втроем они исследовали разные способы кодировки, в том числе при помощи звука.
В 1952 и 1953 годах наработки ученых выкупили компании IBM и Philco. В 1950-1960-е годы произошел настоящий бум в области изысканий способов кодирования графической информации. Наиболее прорывной оказалась технология, предложенная Дэвидом Коллинзом, который пытался упростить учет и маркировку железнодорожных вагонов. Именно он первым предложил кодировать информацию при помощи полосок разного цвета и толщины, а считывать ее световым датчиком. Однако, оборудование Коллинза оказалось слишком громоздким. В итоге в 1973 году инженеры IBM все-таки создали привычный современным людям штриховой код из черных и белых полосок. Сие творение получило название «Universal Product Code». Его создателем считается Джордж Лорер. Первая торговая операция со штрихкодом была осуществлена в 1974 году в супермаркете Marsh города Трой в штате Огайо, США. Это была сделка по продаже жевательной резинки Wrigley.
3. Какие бывают штрихкоды и сканеры для штрихкодов?

Способов штриховой кодировки есть огромное множество.
На изобретении штрихового кода «Universal Product Code» ничего не завершилось, а только началось. На сегодняшний день у нас существуют десятки кодировочных систем. В целом все коды делятся на линейный-одномерные и двумерные сложные. Чаще всего граждане сталкиваются с одномерными кодировками EAN, именно они наносятся на большинство товаров в магазинах. Ярчайшим примером двумерного штрихового кода является QR-код. Несмотря на кажущуюся разницу в графическом отображении, логика что в одномерных, что в двумерных кодах одинаковая – использование сочетаний белых и черных линий. Двумерные коды намного сложнее в своей организации, но логика в них заложена такая же.
Принципиальное отличие (помимо формы) между одномерными и двумерными кодами в количестве той информации, которую можно тем или иным способом зашифровать. Одномерные линейные коды могут «спрятать» в себя небольшое количество простой информации, например, «Помидоры турецкие, 2 рубля 50 копеек». Двумерные коды в сравнении с этим при кажущемся небольшом размере позволяют шифровать наборы данных с объемом до двух листов формата А4. Столь радикальная разница в эффективности кодировок объясняется тем, что одномерные коды шифруют данные используя только ось икс (X). Двумерные коды используют две оси – икс и игрек (XY).
Разными бывают не только штриховые коды, но и оборудование для их считывания. В целом его можно поделить на светодиодное и лазерное. В целом отличие только в цене и эффективности. Светодиодное сканирование работает на очень небольшом расстоянии, но такое оборудование сильно дешевле. Лазерное оборудование дороже, но позволяет считывать коды даже на большом расстоянии. Ну, а теперь к самому интересному.
4. Как функционирует штрихкод простым языком?

На самом деле все просто.
Так как при всей разности форм логика в работе штриховых кодов одинаковая, то разбираться будем на примере простейшего одномерного штрихкода «Code-128». На заре развития микроэлектроники у людей не было технологий, позволяющих компьютеру прочитать с этикетки «Помидоры турецкие. 2 рубля 50 копеек». Для машины эту информацию нужно упростить. Проще всего сделать это, превратив надпись в набор из нулей (0) и единиц (1). Вот только на дворе 1960-е, и оборудование не может прочитать на этикетке «11010000 10111111 11010000 10111110 11010000 10111100 11010000 10111000 11010000 10110100 11010000 10111110 11010001 10000000 11010001 10001011 00001010», точно также как слово «помидоры». Как быть?

Итак, штрихкод - это удобоваримое для простейшего транзистора отображение нулей и единиц.
Все «просто»: нужно зашифровать нули и единицы в удобоваримую для простейшего транзистора форму. Это могут быть черные и белые линии. Как это работает? Каждая черная или белая линия соответствует какому-то набору нулей и единиц. Каждая система кодирования будет содержать свои пары «линия – число». Например, в какой-нибудь «Code-128» самая тонкая черная линия – это «1». Толстая линия из двух тонких – это «11», три тонки «111», белая линия – это «0». Двойная белая – это «00» и так далее. Таким образом «10111110» можно записать как «тонкая черная – тонкая белая - очень толстая черная - тонкая белая». Сделав такой рисунок, получаем штрихкод! Теперь его сможет прочитать фоторезистор в сканере. Каким образом?

Когда луч света попадает на штрихкод он по-разному отражается от белых и черных участков.
Итак, в сканере есть источник света (лазер или светодиод), который пускает луч на штрихкод. Луч света отражается от штрихкода и улавливается фоторезистором. Из-за того, что поверхность штрихкода – это рисунок черное-белое-черное-белое, отраженный луч колеблется. Световые волны «проваливаются» на черных участках штрихкода и «отскакивают» на белых. Фоторезистор принимает эти колебания луча и передает собранную информацию на процессор, который дешифрует «провалился-отскочил» в единицы и нули. Таким образом нарисовав штрихкод, мы сначала закодировали в него нули и единицы, а подсветив штрихкод лазером мы декодировали нули и единицы из рисунка.
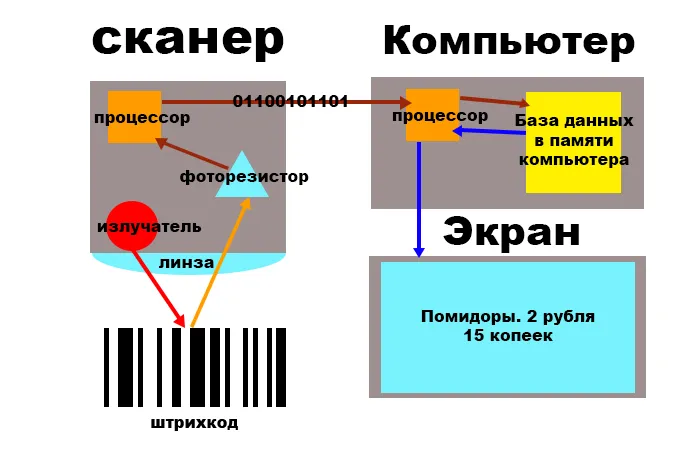
Работает связка рисунок - сканер - компьютер - экран.
Само собой, кодировать «Помидоры турецкие 2 рубля 50 копеек» напрямую в штрихкод было не слишком рационально. Такой штрихкод займет слишком много места. Поэтому используется двойное кодирование. Вся номенклатура товара с ценами шифруется в порядковые номера. Порядковые номера сохраняются в базу данных на компьютере. Каждый порядковый номер товара преобразуется в двоичный код, который записывается в виде штрихкода на этикетке. Работает это примерно следующим образом: сканер считывает штрихкод и преобразует его в двоичный код, процессор компьютера преобразует двоичный код в номер товара, номер товара находится в базе данных, после чего на экран выводится название и цена.
5. И еще маленький моментик…

Участки под цифрами 1, 2, 4, 5 и 1 - технические. Сам код товара только в участке 3.
Отдельно стоит добавить, что во всех штрихкодах содержатся дополнительные символы или полосы, которые носят чисто технических характер. Например, в «Code-128» в начале кода используется большая белая линия, обозначающая начало кода для сканера. Также есть «системные» наборы чередующихся белых и черных полос, которые несут информацию нужную только для самого сканера, например, позволяющую оборудованию понять, штрихкод какой системы перед ним «Code-128» или «EAN-8». Еще один системный участок на рисунке – это стоп-символ, который также нужен сугубо для обеспечения нормальной работы сканера.
Как видите, такие «простые» штуки, как штриховой код и сканер – это настоящая квинтэссенция человеческих знаний в области физики, оптики (раздел физики, изучающий поведение света), микроэлектроники, математики и наверняка чего-нибудь еще.
6. Погоди минуточку, а что за странные цифры под штрихкодом?!

Цифры нужны если код не сработает.
Ах, да, цифры под штрихкодом в большинстве случаев являются всего лишь тем самым порядковым номером товара из базы данных, который и зашифрован с помощью штрихованного кода. Необходим он на тот случай, когда оборудование не сможет прочитать полоски и информацию о товаре придется вводить в кассовый аппарат вручную.
P.S. В Сети есть бесплатные сервисы для перевода чисел и букв в штрихкоды. Например, можно поискать какой-нибудь «Generate Free Barcodes Online». Он позволяет превращать числовые значения в конкретный штрихкод, используя ту или иную систему шифрования.
Можно побаловаться. :)